源代码是程序员之间的交流,不是程序员之间的互打哑谜。───题记
这是郑晖老师的话,我引为题记。我想,这里的读者一定会有大学生,你们在学C语言时,一定遇到过许多求“(i++)+(++i)+(i++)”之类的问题。昨天有人问我,令我一时语塞,研究了半天。今天我要告诉你们,这样的语句是罪恶的。你们也许要说,这明明是考试重点呀。别急,下面我们分成三个部分来组织:在第一部分中,解释为什么它有罪;第二部分,为了解救你们,我们找出解题规律;在第三部分中,给出几个更变态的题目,今后谁出这种题给你,你就用我这里的题目去问他。
一. 这种语句的合法性
C语言的创始人D.M.R在《CPL》中明确指出:
自增与自减运算符只能作用于变量,类似于表达式(i+j)++是非法的。
自增运算实际上包括了一个赋值运算,而表达式不能作赋值运算的左值,因为它没有确定的内存地址。只要你明白 (i+j)=5 是非法的,那就不难理解为什么(i+j)++非法。以此为依据,(i++)+(i++)这个语句中的后一项,是非法的。尽管看起来它只是一个i++,但别忘了,在前一个i++的作用下,后面的“i”本身就已经是表达式了,表达式不能再做++。一般地,在一个语句中,对同一个变量调用多次自增或自减运算,都是非法的。D.M.R还提醒,编译器应在这种情况下给出警告。事实上,gcc确实会对此给出一个:
Warning: operation on ‘i’ may be undefined
这已经够清楚了,无需多言。请编写教学大纲者注意,多年以来,你们一直在用非法语句作考试重点。
二. 如何计算
尽管它非法,但同学们没有执法权,只能任其蹂躏。所以,我们探索一下,编译器在摸不到头脑的情况下,是如何处理这个语句的。我们以 (i++)+(++i)+(++i)+(i++)+(i++) 为例,先将其编译成汇编代码,结果是这样的:
addl -4(%rbp), %eax movl -4(%rbp), %eax addl -4(%rbp), %eax incl -4(%rbp) addl -4(%rbp), %eax addl -4(%rbp), %eax addl -4(%rbp), %eax incl -4(%rbp) incl -4(%rbp) incl -4(%rbp)为了照顾看不懂汇编的朋友,我把它直接对应着翻译成C语言。用变量sum表示要求的和,就是下面这个样子:
i=i+1; sum=i; sum=sum+i; i=i+1; sum=sum+i; sum=sum+i; sum=sum+i; i=i+1; i=i+1; i=i+1这段代码能帮助你理解这个过程,我就不说了,留给你自己探索。下面直接给出我分析的结果:
1. 先将所有的 i++ 改成 i ,然后在整个语句的最后,统一将 i 自增相应的次数(语句中有几个 i++,就在最后自增几次)。我们的例子,这时会变成 i+(++i)+(++i)+i+i; i++; i++; i++;
2. 按照加法的结合性,先将左起前两项相加。如果前两项中含有 ++i,则先算 ++i;
3. 前两项的和作为一项,与第三项相加,以此类推。同样,遇到 ++i,就先算 ++i。
以上就是编译器处理这种语句的规律,当然,这并不是C语言定义的,只是编译器在出错情况下的无奈之举。大家可以用这个方法来解题,下面我就回答昨天一位同学问我的问题:
i=5; 求 (i++)+(++i)+(i++) 的值
按上面的方法做:
1. 先把i++换到最后面,变成 i + (++i) + i ; i++; i++;
2. 从左到右累加,先拿出前两项 i + (++i)。先算 ++i,i 的值变成6,两项相加得12;
3、计算 12 +i,得18。
2010年3月18日星期四
2010年3月14日星期日
MP3 ID3的读取
研究MP3的结构,就不能不研究ID3标签。ID3标签是MP3音乐档案中的歌曲附加讯息,它能够在MP3中附加曲子的演出者、作者以及其它类别资讯,方便众多乐曲的管理。缺少ID3标签并不会影响 MP3的播放,但若没有的话,管理音乐文件也会相当的麻烦。如果你在网上download MP3,里面多半已经写有预设的ID3讯息。ID3,一般是位于一个mp3文件的开头或末尾的若干字节内,附加了关于该mp3的歌手,标题,专辑名称,年代,风格等信息,该信息就被称为ID3信息,ID3信息分为两个版本,v1和v2版。
其中:v1版的ID3在mp3文件的末尾128字节,以TAG三个字符开头,后面跟上歌曲信息。
v2版一般位于mp3的开头,可以存储歌词,该专辑的图片等大容量的信息。
但ID3并不是MP3标签的ISO国际标准,ID3的各种版本目前只是一个近乎事实上的标准,并没有人强迫播放器或者编码程序必须支持它。
ID3V1大概有两个版本,由于ID3V1.0没有包括曲目序号的定义,所以Michael Mutschler在1997年进行了改进,引入了版本1.1。通过占用备注字段的最后两个字节,用一个00字节作标记,另一个字节改为序号,可以让ID3支持曲目编号了。一个字节的空间让ID3 V1.1支持最高到255的曲目序号,考虑到一张唱片超过256个曲目的可能性极小,这个改进还是相当合理的。但ID3V1只有128个字节可以使用,如果要在MP3中储存更多的信息,比如歌词,专辑图片等,显然是无法达到的,于是产生了ID3V2。ID3V2到现在一共有4个版本,但流行的播放软件一般只支持第3版,既ID3v2.3。由于ID3V1记录在MP3文件的末尾,ID3V2就只好记录在MP3文件的首部了。也正是由于这个原因,对ID3V2的操作比ID3V1要慢。而且ID3V2结构比ID3V1的结构要复杂得多,但比前者全面且可以伸缩和扩展。
但我们只需要读出MP3的TITLE,所以只要解析IDV1就够了。
ID3V1的内容和每个标签占用的字节说明如下:
char Header[3]; /*标签头必须是"TAG"否则认为没有标签*/
char Title[30]; /*标题*/
char Artist[30]; /*作者*/
char Album[30]; /*专集*/
char Year[4]; /*出品年代*/
char Comment[30]; /*备注*/
char Genre; /*类型*/
可以定义一个如下的结构来存储MP3信息:
typedef struct _MP3INFO //MP3信息的结构
{
char Identify[3]; //TAG三个字母
//这里可以用来鉴别是不是文件信息内容
char Title[31]; //歌曲名,30个字节
char Artist[31]; //歌手名,30个字节
char Album[31]; //所属唱片,30个字节
char Year[5]; //年,4个字节
char Comment[29]; //注释,28个字节
unsigned char reserved; //保留位,1个字节
unsigned char reserved2; //保留位,1个字节
unsigned char reserved3; //保留位,1个字节
} MP3INFO;
代码可以简单如下:
#include "stdlib.h"
#include "stdio.h"
#include "string.h"
#define MAX 128
typedef struct _MP3INFO //MP3信息的结构
{
char Identify[3]; //TAG三个字母
//这里可以用来鉴别是不是文件信息内容
char Title[31]; //歌曲名,30个字节
char Artist[31]; //歌手名,30个字节
char Album[31]; //所属唱片,30个字节
char Year[5]; //年,4个字节
char Comment[29]; //注释,28个字节
unsigned char reserved; //保留位,1个字节
unsigned char reserved2; //保留位,1个字节
unsigned char reserved3; //保留位,1个字节
} MP3INFO;
int main(int argc, char* argv[])
{
FILE * fp;
unsigned char mp3tag[128] = {0};
MP3INFO mp3info;
char oldname[MAX],newname[MAX],cmd[MAX];
fp = fopen("G:\\mp3\\Debug\\5.mp3","rb");
if (NULL==fp)
{
printf("open read file error!!");
return 1;
}
fseek(fp,-128,SEEK_END);
fread(&mp3tag,1,128,fp);
if(!((mp3tag[0] == 'T'|| mp3tag[0] == 't')
&&(mp3tag[1] == 'A'|| mp3tag[1] == 'a')
&&(mp3tag[2] == 'G'|| mp3tag[0] == 'g')))
{
printf("mp3 file is error!!");
fclose(fp) ;
return 1;
}
memcpy((void *)mp3info.Identify,mp3tag,3); //获得tag
memcpy((void *)mp3info.Title,mp3tag+3,30); //获得歌名
memcpy((void *)mp3info.Artist,mp3tag+33,30); //获得作者
memcpy((void *)mp3info.Album,mp3tag+63,30); //获得唱片名
memcpy((void *)mp3info.Year,mp3tag+93,4); //获得年
memcpy((void *)mp3info.Comment,mp3tag+97,28); //获得注释
memcpy((void *)&mp3info.reserved,mp3tag+125,1); //获得保留
memcpy((void *)&mp3info.reserved2,mp3tag+126,1);
memcpy((void *)&mp3info.reserved3,mp3tag+127,1);
fclose(fp);
if (strlen(mp3info.Title) == 0)
{
printf("title is null\n");
return 1;
}
strcpy(oldname,"5.mp3");
sprintf(newname,"%s.mp3",mp3info.Title);
sprintf(cmd,"rename G:\\mp3\\Debug\\%s %s",oldname,newname);
printf("%s\n", cmd);
system(cmd);
return 0;
}
更新:
我尝试读出ID3v1的四个字段,发现因为mp3info没有初始化,显示出来的字段有些有乱码,所以在mp3info的定义语句后,通过memset()来初始化mp3info结构。结果在vs2008环境中,出现了一个很奇怪的错误:“error C2143: 语法错误 : 缺少“;”(在“类型”的前面)”。一番搜索无解后,发现调换下面那句char oldname[MAX],newname[MAX],cmd[MAX]; 与 memset()的顺序,就没有报错了。不知所以然。
2010年3月10日星期三
【转】学之者生,用之者死――ACE历史与简评
陈硕 (giantchen_AT_gmail)
2010 March 10
ACE 是现代面向对象网络编程的鼻祖,确立了许多重要模式,如 Reactor、Acceptor 等,重要到我们甚至觉得网络编程就应该是那样的。但为什么 ACE 叫好不叫座?大名鼎鼎却使用者寥寥?本文谈谈我的个人观点。
ACE 是一套重量级的 C++ 网络库,早期版本由 Douglas Schmidt 独自开发,后来有 40 余名学生与工作人员也贡献了大量代码。作者 Douglas Schmidt 凭借它发表了 30 余篇学术论文。ACE 的一大特点是融合了 Douglas Schmidt 提出的很多面向对象网络编程的设计模式,并且具有不可思议的跨平台能力
1 ACE 历史
先说说 ACE 之父 Douglas Schmidt 的个人经历:
- 1990 年在加州大学 Irvine 分校获计算机硕士学位;
- 1994 年在同一学校获计算机博士学位,论文《An Object-Oriented Framework for Experimenting with Alternative Process Architectures for Parallelizing Communication Subsystems》。从论文内容看,主要工作就是后来大名鼎鼎的 ACE framework,文中叫 ASX framework。
- 1994 年博士毕业后前往华盛顿大学任助理教授,后升至副教授
- 2003 年起在 Vanderbilt 大学任正教授至今
我相信 ACE 是 Douglas 在读博期间的主要工作,ACE 这个名字最早出现在 1993 年 12 月的一篇会议论文上,Douglas 的这篇文章获得了“最佳学生论文”奖。在此之前,Douglas 已经用 ASX 等其他名字发表了内容相近的文章。
我能下载到的最早的 ACE 版本是 4.0.32,有大约 86,000 行 C++ 代码,代码的时间戳是 1998 年 10 月 22 日。早期 ACE 由 Douglas Schmidt 个人独立开发,从 ChangeLog 得知,1993 年 11 月 ACE 的版本号是 2.12。到了 1995 年 9 月,才有第一次出现其他开发者。在 1993~1996 年间的 684 次改动中,Douglas 一个人贡献了 529 次,另外几个主要开发者以及他们的修改次数分别是 Prashant Jain (58)、Tim Harrison (42)、David Levine (28)、Irfan Pyarali (20)、Jesper S. M|ller (5)。
从整个 ChangeLog 看,从 1993 年到 2010 年 3 月有 19,000 余次改动。有超过 200 人修改过代码,其中 23 个人的 check-in 次数大于 100,排名前 12 的代码修改者为:
3635 Johnny Willemsen (活跃年份:2001~今)
2586 Douglas C. Schmidt(原作者,活跃年份:1993~今)
1861 Steve Huston (活跃年份:1997~今)
1197 David L. Levine (活跃年份:1996~2000)
962 Nanbor Wang (活跃年份:1998~2003)
907 Ossama Othman (活跃年份:1999~2005)
865 Chad Elliott (活跃年份:2000~今)
823 Bala Natarajan (活跃年份:1999~2004)
708 Carlos O'Ryan (活跃年份:1997~2001)
544 J.T. Conklin (活跃年份:2004~2008)
479 Irfan Pyarali (活跃年份:1996~2003)
368 Darrell Brunsch (活跃年份:1997~2001)
看到这些“活跃年份”,你的第一反应是什么?我想到的是,这些人会不会多半是 Douglas 指导的研究生?我猜他们在读研期间参与改进 ACE,把工作内容写成论文发表,然后毕业走人。或许这能解释 ACE 代码风格的多样性。
在浏览代码历史的过程中,我还发现一个很有意思的现象,在 2008 年 3 月 4 日,某人不小心把整个 ACE 的源代码树删除了:
https://svn.dre.vanderbilt.edu/viewvc/Middleware?view=revision&revision=80824
随后又很快恢复:
https://svn.dre.vanderbilt.edu/viewvc/Middleware?view=revision&revision=80826
干这件事情的老兄在 2005~2009 这几年里一共 check in 了 120 余次。你对这件事情怎么看?你们的开发团队里有这样的人吗?
2 事实与思考
1. 除了 Douglas Schmidt 和 Stephen Huston 写的三本书籍之外,没有其他专著讲 ACE。
究竟是 ACE 太好用了,以至于无需其他书来讲解,还是太难用了,讲也讲不明白?抑或根本就没人在乎?
《C++ 网络编程 第1卷》《C++ 网络编程 第2卷》《ACE 程序员指南》这三本书先后于 2001、2002、2003 年出版,之后再无更新。在同一时期,同样在网络编程领域,尽管 W. Richard Stevens 在 1999 年去世,他的 UNP 和 APUE 仍然由别人续写了新版。讲 C 语言 Sockets API 的书尚且不断更新,上层封装的 C++ 居然无动于衷?真的是封装到位了,屏蔽了这些变化?
UNP 的可操作性很强,读前面几章,就能上手编写简单的网络程序,看完大半本书,网络编程基本就算入门了,能编写一般应用的网络程序。相反,读完 ACE 那几本书,对于简单的网络编程任务还是感觉无从下手,这是因为书写得不好,还是 ACE 本身不好用?
2. ACE 很难用,非常容易用错
我不止听到一个人对我说,他们在项目里尝试过 ACE,不是中途放弃,因为出了问题无法解决;就是勉强交差,并且从下一个项目起坚决不用。我听到的另一个说法是,ACE 教程的例子必须原封不动地抄下来,改一点点就会出漏子。不巧的是,ACE 的例子举来举去就是个 Logging 服务器,让人想照猫画虎也无从下手。在最近的《代码之美》一书中,Douglas Schmidt 再次拿它为例,说明他真的很喜欢这个例子。
用 ACE 编程如履薄冰,生怕在阴沟里翻船,不知道它背后玩了什么把戏。相反,用 10 来个 Sockets 系统调用就能搞定网络编程,我感觉比使用 ACE 难度要小。为什么“高级”工具反而没有低级工具顺手呢?
不好用的直接后果是少有人用,放眼望去,目前涉及网络的 C++ 开源项目里边,鲜有用 ACE 作为通信平台的(我知道的只有 Mangos)。相反,libevent 这个轻量级的 IO multiplexing 库有 memcached 这样的著名用户。
3. ACE 代码质量不高,更像是一个研究项目,而不是工业界的产品
读 ACE 现在的代码,一股学生气扑面而来,感觉像在读实习生写的代码。抛开编码风格不谈,这里举三个“硬伤”:
- sleep < 2ms
在某些早期的 Linux 内核上,如果 select/poll 的等待时间小于 2ms,内核会采用 busy-waiting。这是极大的 CPU 资源浪费,而 ACE 似乎没有考虑避免这一点。
- Linux TCP self-connection
Linux 的 TCP 实现有一个特殊“行为”,在某些特殊情况下会发起自连接。而 Linux 网络协议栈的维护者认为这是一个 feature,不是 bug,拒绝修复。通常网络应用程序不希望出现这种情况,我见过的好的网络库会有意识地检查并断开这种连接,然而 ACE 漠然视之。
- timeval on 64-bit
ACE_Time_Value 类直接以 struct timeval 为成员变量,保存从 Epoch 开始的微秒数。这在 32-bit 下没问题,对象大小是 8 字节。到了 LP64 模式的 64-bit 平台,比如 Linux,对象大小变为 16 字节,这么做就不够好了。我们可以直接用 int64_t 来保存这个以微秒为单位的时间,64-bit 整数能存下上下 30 万年,足够用了。减小对象大小并不是为了节约几个字节的内存,而是方便函数参数传递。在 x86-64 上,这种 8 字节的结构体可以用 64-bit 寄存器直接传参,也就是说 pass by value 会比 pass by reference 更快。对于一般的应用程序而言,要不要这么做值得商榷。对于底层的 C++ 网络库,不加区分地使用 pass by reference 会让人怀疑作者知其然不知其所以然。
对于以上几点情况,我怀疑 ACE 根本没用在 Linux 大规模生产环境下使用过,我只能期望它在别的平台表现好一些了。ACE 的作者们似乎更注重验证新想法,然后发论文,而不是把它放到工业环境中反复锤炼,打造为靠得住的产品。(类似 Minix 与 Linux 的关系。)
4. 移植性很好,支持我知道的和不知道的很多平台
ACE 的意义在于让我们明白了C++代码可以做到可移植,并展示了这么做会付出多么巨大的代价。不细说了,读过 ACE 代码的人都明白。
从代码质量上看,ACE 做到了能在这些平台上运行,但似乎没有在哪个平台占据主导地位。有没有哪个平台的网络编程首选 ACE?
出现这一状况的原因是,跨平台和高性能是矛盾的。跨平台意味着要抽象出多个平台的共性,以最 general 的方式编写上层代码。而高性能则要求充分发挥平台的特性,剑走偏锋,用尽平台能提供的一切加速手段,哪怕与其他平台不兼容。网络编程对此尤为敏感。
我不知道 ACE 的性能如何,因为在各项性能评测榜上基本看不到它的名字(c10k 里就没有 ACE 的身影)。另外,Buffer class 的好坏直接反应了网络库对性能的追求,ACE 提供了比 std::deque<uint8_t> 更好的输入输出 Buffer 吗?(我不是说 deque 有多好,它基本是 fail-safe 的选择而已。)
5. ACE 过于复杂,甚至比它试图封装的对象更复杂。
(这里的代码行数均为 wc 命令的粗略估计。)
ACE 5.7 自身(不含 TAO 和 CIAO)有 30 万行 C++ 代码(Douglas 自己给出的数据是 25 万行,可能指的是略早的版本),这是一个什么概念呢?我们来看 TCP/IP 协议栈本身的实现有多少行:(均不含 IPv6)
- TCPv2 列出的 BSD4.4-Lite 完整 TCP/IP 协议栈代码有 15,000 行,其中 4,500 行 TCP 协议,800 行 UDP 协议,2,500 行 IP 协议
- Linux 1.2.13 完整的 TCP/IP 协议栈有 2 万多行 (net/inet)
- Linux 2.6.32.9 的 TCP/IP 协议栈有 6 万多行 (net/ipv4)
- FreeBSD 8.0 的 TCP/IP 协议栈有 5 万多行 (sys/netinet, 不含 sctp)
换句话说,ACE 用 30 万行 C++ 代码“封装”了不到 10 万行 C 代码(且不论 C++ 代码的信息密度比 C 大),这是不是头重脚轻呢?我理解的“封装”是把复杂的东西变简单,但 ACE 好像走向了另一个方向,把不那么复杂的东西变复杂了。
这个对比数字可能不太准确,因为 ACE 还封装了很多其他东西,请看。http://www.dre.vanderbilt.edu/Doxygen/5.7.7/html/ace/inherits.html 和 http://www.dre.vanderbilt.edu/Doxygen/5.7.7/html/ace/hierarchy.html
以下两张类的继承关系图片请在新窗口打开:
http://www.dre.vanderbilt.edu/Doxygen/5.7.7/html/ace/a06178.png
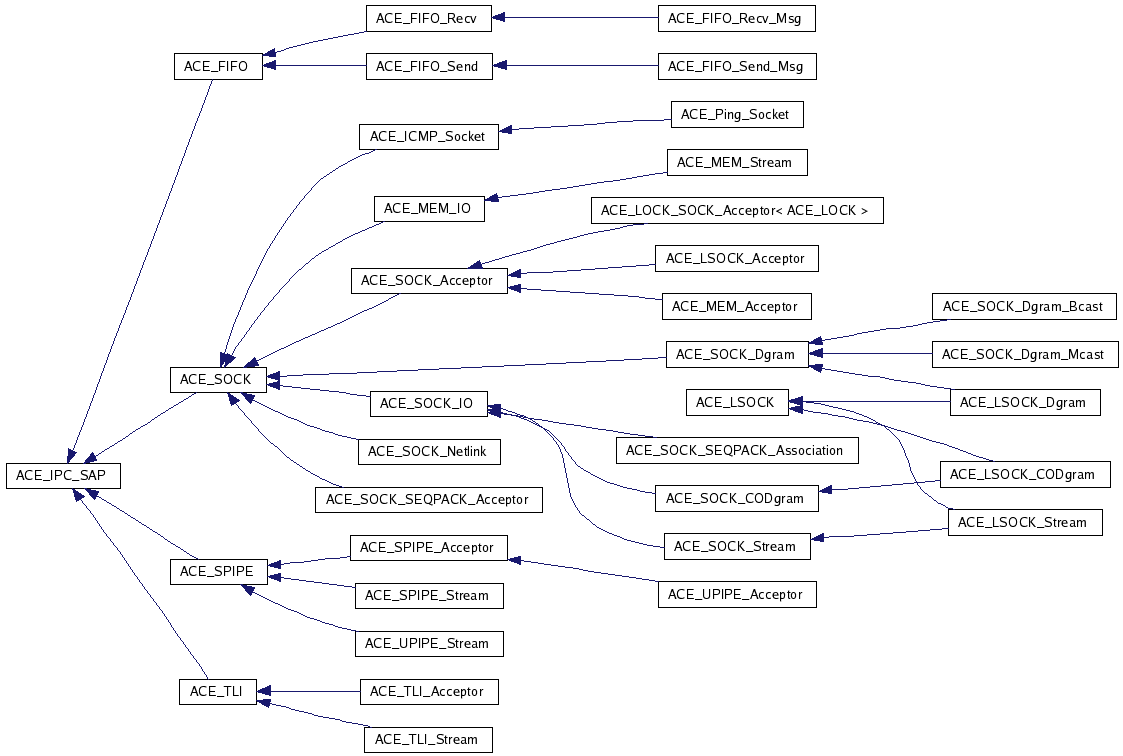{kind=link}
http://www.dre.vanderbilt.edu/Doxygen/5.7.7/html/ace/a06347.png
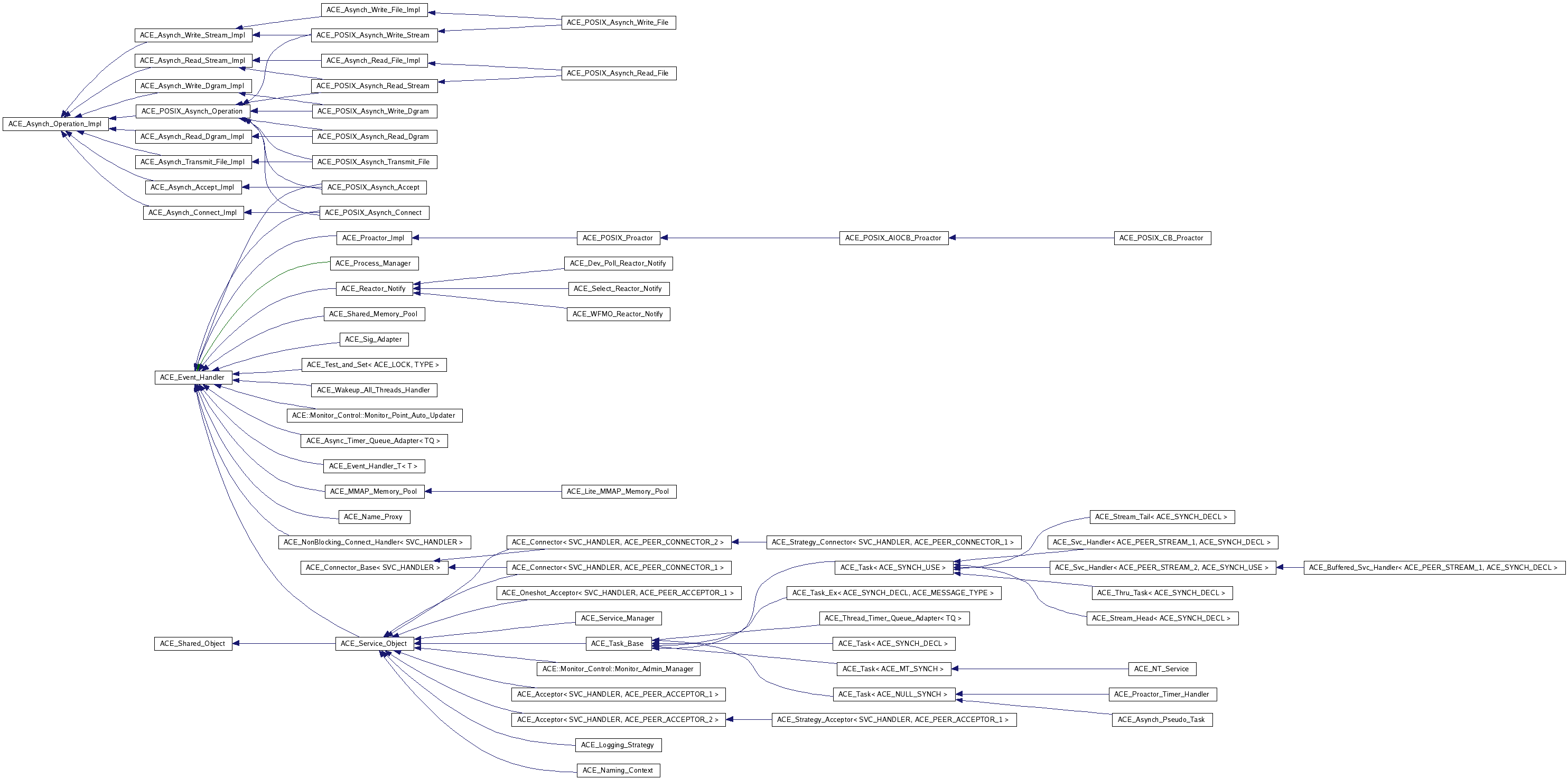{kind=link}
Douglas 说 ACE 包含了 40 人年的工作量,对此我毫不怀疑。但是,网络编程真的需要这么复杂吗?TCP/IP 协议栈的实现也没这么多工作量嘛。或许只有 CORBA 这样的应用才会用到这么复杂的东西?那么为什么 ICE 在重新实现 CORBA 的时候没有基于 ACE 呢?是不是因为 ACE 架子拉得大,底子并不牢?
3 ACE 的意义
ACE 对于面向对象、设计模式和网络编程具有重大历史和现实意义。
ACE 诞生之时,正是 90 年代初期面向对象技术的高速发展期,ACE 一定程度上是作为面向对象技术的成功案例来宣传的。
在 1994 年前后,Unix 分为两个阵营,AT&T 的 SVR4 与 BSD 的 BSD4.x,这两家的 IO multiplexing 不完全兼容。比如 SVR4 提供 poll 调用,而 BSD 提供 select 调用。ACE 当时的宣传点之一是用面向对象技术屏蔽了两个平台的差异,提供了统一的 Reactor 接口。
【接下来,poll 在 1996 年 9 月 7 号加入 NetBSD,并随 NetBSD 1.3 于 1998 年 1 月 4 号发布。随后 FreeBSD 3.0 也支持 poll,1998 年 10 月发布。Linux 很早就支持 select,从 2.1.23 内核起支持 poll,发布日期为 1997 年 1 月 26 号。也就是说,到了 1998 年,平台差异被暂时抹平了。随后 epoll、/dev/poll、kqueue 以性能为名,再次扩大了平台差异。当然,Windows 至今不支持 poll。】
ACE 的设计似乎过于强调面向对象的灵活性,一些不该使用虚函数的地方也提供了定制点,比如 ACE_Timer_Queue 就应是个具体类,而不是允许用户 override schedule/cancel/expire 之类的具体操作。面向对象中,“继承”的目的是为了被复用,而不是去复用基类的代码。
查其文献,Reactor 在 1993 年登上《C++ Report》杂志的时候,文章标题还比较朴素,挂着“面向对象”的旗号:
- 《The Reactor: An Object-Oriented Interface for Event-Driven UNIX I/O Multiplexing (Part 1 of 2)》
- 《The Object-Oriented Design and Implementation of the Reactor: A C++ Wrapper for UNIX I/O Multiplexing (Part 2 of 2)》
转眼到了 1994 年,也就是《设计模式》成书的那一年,Douglas 开始写文章言必称 pattern:
- Reactor 变成了 pattern,收录于《Pattern Languages of Program Design》一书(An Object Behavioral Pattern for Demultiplexing and Dispatching Handles for Synchronous Events)。这篇文章比前面两篇难懂,如果直接阅读的话。
- Acceptor 是 pattern (A Design Pattern for Passively Initializing Network Services),
- Connector 也是 pattern(A Design Pattern for Actively Initializing Network Services),
- Proactor 还是 pattern(An Object Behavioral Pattern for Demultiplexing and Dispatching Handlers for Asynchronous Events),
- 居然连 Thread-Specific Storage 都成了 pattern(An Object Behavioral Pattern for Accessing per-Thread State Efficiently)。
- 还有 Non-blocking Buffered I/O,也是 pattern (An Object Behavioral Pattern for Communication Gateways)。
似乎 "pattern" 这个字样成了发文章的通行证,这股风气直到 2000 左右才刹住。之后这些论文集结出版,以《Pattern-Oriented Software Architecture》为名出了好几本书,ACE 的内容主要集中在第二卷。(请留意,原来的提法是 Object-Oriented,现在变成了 Pattern-Oriented,似乎软件开发就应该像糖果厂生产绿豆糕,用模子一个个印出来完事。)
ACE 就像一个 pattern 大观园,保守估计有 10 来种 patterns 藏身其中,形成了一套模式语言(《Applying a Pattern Language to Develop Application-level Gateways》),这还不包括 GoF 定义的一般意义下的 OO pattern。
通过 ACE 来学习网络编程,那是本末倒置,因为它教不了你任何 UNP 以外的知识。(Windows 网络编程?)
然而,如果要用面向对象的方式来搞网络编程,那么 ACE 的思想(而不是代码)是值得效仿的,毕竟它饱含了 Douglas Schmidt 等学者的心血与智慧。学得好的例子有 Apache Mina、JBoss Netty、Python Twisted、Perl POE 等等。
这就是我说“学之者生,用之者死”的含义。
4 ACE 文献导读
Douglas Schmidt 写了很多 ACE 的文章,其中不乏内容相近的作品。读他的文章,首选发表在技术杂志上的文章(比如 C++ Report),而不是发表在学术期刊或会议上的论文。前者的写作目的是教会读者技术,后者则往往是展示作者的新思路新想法,技术文章比学术论文要好读得多。
由于当时面向对象技术尚在发展,Douglas 文章里的图形很有特色,不是现在规范的 UML 图(那会儿 UML 还没定型呢),而是像变形虫一样的类图(经pinxue指出,这种图是 Grady Booch 发明的),放在一堆文献里也很容易认出来。
如果要用 ACE 的代码来验证文章的思路,我建议阅读和文章同时期的 4.0 版本代码,代码风格比较统一,代码量也不大,便于理解。
下面介绍几篇有代表性的论文。
- 1993 年 12 月第 11 届 SUG 会议,《The ADAPTIVE Communication Environment: Object-Oriented Network Programming Components for Developing Client/Server Applications》,获得最佳学生论文奖。这是我找到的最早一篇以 ACE 为题的论文。
- 1994 年 6 月第 12 届 SUG 会议,《The ADAPTIVE Communication Environment: An Object-Oriented Network Programming Toolkit for Developing Communication Software》,获得最佳学生论文奖。
以上两篇文章实际上内容基本相同,都是对 ACE 的概要介绍,看第二篇即可,第一次没看懂也没关系。
剩下要看的是一篇 Socket OO 封装、四篇 Reactor、三篇 Acceptor-Connector、一篇 Proactor。这些文章前面大多都给了链接,其余的这里补充一下:
- IPC_SAP: A Family of Object-Oriented Interfaces for Local and Remote Interprocess Communication
- The Design and Use of the ACE Reactor
- Acceptor and Connector -- A Family of Object Creational Patterns for Initializing Communication Services 这篇论文其实可以不用看,因为它不过是把前面两篇发表在 C++ Report 上的文章合到了一起。
不想看这 10 篇论文的话,读中译本《C++ 网络编程 第1卷》《C++ 网络编程 第2卷》《ACE 程序员指南》也行,翻译质量都不错。
5 设想中的 C++ 网络库
谈了这么多 ACE 的优缺点,那么我心目中理想的网络库是什么样子的呢?
- 线程安全,支持多核多线程
- 不考虑可移植性,不跨平台,只支持 Linux,不支持 Windows。
- 在不增加复杂度的前提下可以支持 FreeBSD/Darwin,方便将来用 Mac 作为开发用机,但不为它做性能优化。也就是说 IO multiplexing 使用 poll 和 epoll。
- 主要支持 x86-64,兼顾 IA32
- 不支持 UDP,只支持 TCP
- 不支持 IPv6,只支持 IPv4
- 不考虑广域网应用,只考虑局域网
- 只支持一种使用模式:non-blocking IO + one event loop per thread,不考虑阻塞 IO
- API 简单易用,只暴露具体类和标准库里的类,不使用 non-trivial templates,也不使用虚函数
- 只满足常用需求的 90%,不面面俱到,必要的时候以 app 来适应 lib
- 只做 library,不做成 framework
- 争取全部代码在 5000 行以内(不含测试)
- 以上条件都满足时,可以考虑搭配 Google Protocol Buffers RPC
我觉得网络库要解决现实的问题,满足现实的需要,而不是把 features/patterns 堆在那里等别人来用。应该先有应用,再提炼出库。而不是先造库,然后寻求应用。上面这样一个网络库就能满足我目前的全部需要。
2010年2月28日星期日
C++ Keywords: typedef
(1)定义已知类型的别名
In C++, the typedef keyword allows you to create an alias for a data type. The formula to follow is:
typedef [attributes] DataType AliasName;
The typedef keyword is required. The attribute is not.
例子:
typedef short SmallNumber;
typedef unsigned int Positive;
typedef double* PDouble;
typedef string FiveStrings[5];
1. In typedef short SmallNumber, SmallNumber can now be used as a data type to declare a variable for a small integer.
2. In the second example, typedef unsigned int Positive, The Positive word can then be used to declare a variable of an unsigned int type.
3. After typedef double* PDouble, the word PDouble can be used to declare a pointer to double.
4. By defining typedef string FiveStrings[5], FiveStrings can be used to declare an array of 5 strings with each string being of type string.
SmallNumber temperature = -248;
Positive height = 1048;
PDouble distance = new double(390.82);
FiveStrings countries = { "Ghana", "Angola", "To“,"Tunisia", "Cote d'Ivoire" };
值得注意的写法
typedef char* PSTR, CHAR;
CHAR为char型,所以更好的写法是
typedef char *PSTR, CHAR; 或者 typedef char CHAR, *PSTR;
(2) 定义函数类型别名
The typedef keyword can also be used to define an alias for a function. In this case, you must specify the return type of the function and its type(s) of argument(s), if any. Another rule is that the definition must specify that it is a function pointer。
例子:
typedef double (*Addition)(double value1, double value2);
double Add(double x, double y)
{
double result = x + y;
return result;
}
Addition plus;
plus = Add;
plus(3855.06, 74.88);
例子2:(msdn上)
The following example provides the type DRAWF for a function returning no value and taking two int arguments:
typedef void DRAWF( int, int );
After the above typedef statement, the declaration
DRAWF box;
would be equivalent to the declaration
void box( int, int );
(3)
总结typedef的语法为:
More generally, after the word “typedef”, the syntax looks exactly like what you would do to declare a variable of the existing type with the variable name of the new type name. Therefore, for more complicated types, the new type name might be in the middle of the syntax for the existing type. For example:
typedef char (*pa)[3]; // "pa" is now a type for a pointer to an array of 3 chars
typedef int (*pf)(float); // "pf" is now a type for a pointer to a function which takes 1 float argument and returns an int
C语言函数入栈顺序与可变参数函数
函数调用时如果出现堆栈异常,十有八九是由于函数调用约定不匹配引起的。比如动态链接库a有以下导出函数:
动态库生成的时候采用的函数调用约定是__stdcall,所以编译生成的a.dll中函数MakeFun的调用约定是_stdcall,也就是函数调用时参数从右向左入栈,函数返回时自己还原堆栈。现在某个程序模块b要引用a中的MakeFun,b和a一样使用 C++方式编译,只是b模块的函数调用方式是__cdecl,由于b包含了a提供的头文件中MakeFun函数声明,所以MakeFun在b模块中被其它调用MakeFun的函数认为是__cdecl调用方式,b模块中的这些函数在调用完MakeFun当然要帮着恢复堆栈啦,可是MakeFun已经在结束时自己恢复了堆栈,b模块中的函数这样多此一举就引起了栈指针错误,从而引发堆栈异常。宏观上的现象就是函数调用没有问题(因为参数传递顺序是一样的),MakeFun也完成了自己的功能,只是函数返回后引发错误。解决的方法也很简单,只要保证两个模块的在编译时设置相同的函数调用约定就行了。
在了解了函数调用约定和函数的名修饰规则之后,再来看在C++程序中使用C语言编译的库时经常出现的LNK2001错误就很简单了。还以上面例子的两个模块为例,这一次两个模块在编译的时候都采用__stdcall调用约定,但是a.dll使用C语言的语法编译的(C语言方式),所以a.dll的载入库a.lib中MakeFun函数的名字修饰就是“_MakeFun@4”。b包含了a提供的头文件中MakeFun函数声明,但是由于b采用的是C++语言编译,所以MakeFun在b模块中被按照C++的名字修饰规则命名为“?MakeFun@@YGJJ@Z”,编译过程相安无事,链接程序时c++的链接器就到a.lib中去找“?MakeFun@@YGJJ@Z”,但是a.lib中只有“_MakeFun@4”,没有“?MakeFun@@YGJJ@Z”,于是链接器就报告:
error LNK2001: unresolved external symbol ?MakeFun@@YGJJ@Z
解决的方法和简单,就是要让b模块知道这个函数是C语言编译的,extern"C"可以做到这一点。一个采用C语言编译的库应该考虑到使用这个库的程序可能是C++程序(使用C++编译器),所以在设计头文件时应该注意这一点。通常应该这样声明头文件:
这样C++的编译器就知道MakeFun的修饰名是“_MakeFun@4”,就不会有链接错误了。
许多人不明白,为什么我使用的编译器都是VC的编译器还会产生“error LNK2001”错误?其实,VC的编译器会根据源文件的扩展名选择编译方式,如果文件的扩展名是“.C”,编译器会采用C的语法编译,如果扩展名是 “.cpp”,编译器会使用C++的语法编译程序,所以,最好的方法就是使用extern "C"。
==============================================
大家会注意到,像gcc之类的编译器也是采用__cdecl方式,这样对于printf(“%d %d“,i++,i++)之类的输出结果的疑问就迎刃而解了。
另外引出的一个问题是C语言的变参数函数,对于这部分估计很少大学会涉及到,但这的确是C语言很常见的一个特性,比如printf等。上面提到对于可变参数的支持,需要由函数调用者负责清除栈中的函数参数,但为什么非要这样才可以支持变参数呢?函数调用所涉及到的参数传递是通过栈来实现的,子函数从栈中读取传递给它的参数,如果是从左向右压栈的话那么子函数的最后一个参数在栈顶,然后依次是倒数第二个参数......;如果是从右向左压栈的话那么子函数的第一个参数在栈顶,然后依次是第二个参数......,压栈的顺序问题决定了子函数读取其参数的位置。对于变参数的函数本身来讲,并不知道有几个参数,需要某些信息才能知道,对于printf来讲,就是从前面的格式化字符串fmt来分析出来,一共有几个参数。所以被调函数返回清理栈的方式,对于可变参数是无法实现的,因为被调函数不知道要弹出参数的数量。而对于函数调用着,自己传递给被调函数多少参数(通过把参数压栈)当然是一清二楚的,这样被调函数返回后的堆栈清理也就可以做到准确无误了(不会多也不会少地把参数清理干净)。
===============================================
long MakeFun(long lFun);
动态库生成的时候采用的函数调用约定是__stdcall,所以编译生成的a.dll中函数MakeFun的调用约定是_stdcall,也就是函数调用时参数从右向左入栈,函数返回时自己还原堆栈。现在某个程序模块b要引用a中的MakeFun,b和a一样使用 C++方式编译,只是b模块的函数调用方式是__cdecl,由于b包含了a提供的头文件中MakeFun函数声明,所以MakeFun在b模块中被其它调用MakeFun的函数认为是__cdecl调用方式,b模块中的这些函数在调用完MakeFun当然要帮着恢复堆栈啦,可是MakeFun已经在结束时自己恢复了堆栈,b模块中的函数这样多此一举就引起了栈指针错误,从而引发堆栈异常。宏观上的现象就是函数调用没有问题(因为参数传递顺序是一样的),MakeFun也完成了自己的功能,只是函数返回后引发错误。解决的方法也很简单,只要保证两个模块的在编译时设置相同的函数调用约定就行了。
在了解了函数调用约定和函数的名修饰规则之后,再来看在C++程序中使用C语言编译的库时经常出现的LNK2001错误就很简单了。还以上面例子的两个模块为例,这一次两个模块在编译的时候都采用__stdcall调用约定,但是a.dll使用C语言的语法编译的(C语言方式),所以a.dll的载入库a.lib中MakeFun函数的名字修饰就是“_MakeFun@4”。b包含了a提供的头文件中MakeFun函数声明,但是由于b采用的是C++语言编译,所以MakeFun在b模块中被按照C++的名字修饰规则命名为“?MakeFun@@YGJJ@Z”,编译过程相安无事,链接程序时c++的链接器就到a.lib中去找“?MakeFun@@YGJJ@Z”,但是a.lib中只有“_MakeFun@4”,没有“?MakeFun@@YGJJ@Z”,于是链接器就报告:
error LNK2001: unresolved external symbol ?MakeFun@@YGJJ@Z
解决的方法和简单,就是要让b模块知道这个函数是C语言编译的,extern"C"可以做到这一点。一个采用C语言编译的库应该考虑到使用这个库的程序可能是C++程序(使用C++编译器),所以在设计头文件时应该注意这一点。通常应该这样声明头文件:
#ifdef _cplusplus
extern "C" {
#endif
long MakeFun(long lFun);
#ifdef _cplusplus
}
#endif
这样C++的编译器就知道MakeFun的修饰名是“_MakeFun@4”,就不会有链接错误了。
许多人不明白,为什么我使用的编译器都是VC的编译器还会产生“error LNK2001”错误?其实,VC的编译器会根据源文件的扩展名选择编译方式,如果文件的扩展名是“.C”,编译器会采用C的语法编译,如果扩展名是 “.cpp”,编译器会使用C++的语法编译程序,所以,最好的方法就是使用extern "C"。
==============================================
大家会注意到,像gcc之类的编译器也是采用__cdecl方式,这样对于printf(“%d %d“,i++,i++)之类的输出结果的疑问就迎刃而解了。
另外引出的一个问题是C语言的变参数函数,对于这部分估计很少大学会涉及到,但这的确是C语言很常见的一个特性,比如printf等。上面提到对于可变参数的支持,需要由函数调用者负责清除栈中的函数参数,但为什么非要这样才可以支持变参数呢?函数调用所涉及到的参数传递是通过栈来实现的,子函数从栈中读取传递给它的参数,如果是从左向右压栈的话那么子函数的最后一个参数在栈顶,然后依次是倒数第二个参数......;如果是从右向左压栈的话那么子函数的第一个参数在栈顶,然后依次是第二个参数......,压栈的顺序问题决定了子函数读取其参数的位置。对于变参数的函数本身来讲,并不知道有几个参数,需要某些信息才能知道,对于printf来讲,就是从前面的格式化字符串fmt来分析出来,一共有几个参数。所以被调函数返回清理栈的方式,对于可变参数是无法实现的,因为被调函数不知道要弹出参数的数量。而对于函数调用着,自己传递给被调函数多少参数(通过把参数压栈)当然是一清二楚的,这样被调函数返回后的堆栈清理也就可以做到准确无误了(不会多也不会少地把参数清理干净)。
===============================================
Solution of fatal error RC1004: unexpected end of file found
After you modified your reource.h, you may got this error:
fatal error RC1004: unexpected end of file found.
It's a bug of the resource compiler.
The solution is adding a blank line or two to the end of the file and build again.
订阅:
博文 (Atom)