--limit-rate=200k
限速200kB/s
wget --limit-rate=300k http://mirrors.163.com/ubuntu-releases/9.10/ubuntu-9.10-desktop-amd64.iso
2011年6月26日星期日
Cygwin
前天刚安装MSYS,用得还没上手,就又看上了Cygwin,谁叫Cygwin 软件比较多呢。这种该也是浪费时间的一种方式吧。
安装Cygwin用的是学校的安装源,速度还算可以吧。我的环境是Win XP SP3 英文版,Language for non-unicode选了Chinese PRC。
(1) terminal的选择
没怎么用过终端,Ubuntu下自带的Gnome Terminal 都说很差劲,我倒觉得挺华丽和方便的,说明我对终端的使用程度不高,还没有培养出审美能力。
a. rxvt
推荐比较多的是用rxvt,好吧,那就用rxvt吧。配置rxvt显示中文就让我焦头烂额了一整天,结果还是没有搞好。最多只能显示中文,但是无法输入中文。我失败的配置如下:
~/.bashrc 中添加
网上的说法是要使rxvt能够输入中文,在~/.inputrc中添加:
我试过,没效果。在这上面浪费了我好多时间。不过,在 ~/.inputrc中添加
b. urxvt
还有个推荐说是urxvt,也就是rxvt的unicode版。在cygwin中,这是需要X 环境的。我没安装。
待实验。
c. mintty
这是我现在用的终端,是在cygwin的安装源中。无需设置,即可方便显示中文和输入中文。我让ls 显示颜色以及忽略大小写。
d. cmd
为什么不直接用cmd.exe 开 bash 呢? 也是无需设置显示中文和输入中文。但是,我不知道为什么我不用,或许是装13。
(2) Home路径设置
默认情况下,Home路径在/home/yourname,而/就是cygwin安装目录。很显然,你不会真把这个目录当作home目录,文件全存放在这吧?可以手动修改/etc/passwd文件来设置你喜欢的目录,路径格式使用cygwin风格,比如d:/tizzy目录,在此处应该为/cygdrive/d/tizzy 。
(3) 调用其他程序
居然cygwin是在windows上,说明windows上也有一些你比较顺手的程序,或者已经懒得去用cygwin中类似功能的程序。
为了能够在终端中调用,把每个程序的路径加入到PATH,我是直接加在系统PATH中。然后在目录下建个文件,起个你喜欢的名字,用来启动程序。比如:
我在widnows下用PDFXCview.exe来阅读pdf,安装路径在D:\Program Files\Tracker Software\PDF Viewer,把这个路径加入到系统PATH,在目录下建 pdfview 文件(是的,没有后缀),文件内容为
update:Jun 30,2011
本来以为上面设置就可以,后来打开pdf只能显示第一页,不知道原因。如果直接调用windows下的程序(因为已加入到PATH中),是可以正常打开,但是会占用一个终端,这是我不希望看到的。
实际上,cygwin提供了一个命令 cygstart,可以用来打开任何文件,默认会调用windows下的关联程序来打开,而且不占用终端。这正是我所需要的。
安装Cygwin用的是学校的安装源,速度还算可以吧。我的环境是Win XP SP3 英文版,Language for non-unicode选了Chinese PRC。
(1) terminal的选择
没怎么用过终端,Ubuntu下自带的Gnome Terminal 都说很差劲,我倒觉得挺华丽和方便的,说明我对终端的使用程度不高,还没有培养出审美能力。
a. rxvt
推荐比较多的是用rxvt,好吧,那就用rxvt吧。配置rxvt显示中文就让我焦头烂额了一整天,结果还是没有搞好。最多只能显示中文,但是无法输入中文。我失败的配置如下:
~/.bashrc 中添加
#中文环境
#设置完可以显示中文
export LC_CTYPE=zh_CN.GB2312
export LANG=zh_CN.GB2312
#ls 显示颜色
alias ls='ls --color --show-control-chars'
网上的说法是要使rxvt能够输入中文,在~/.inputrc中添加:
set meta-flag on
set convert-meta off
set input-meta on
set output-meta on
我试过,没效果。在这上面浪费了我好多时间。不过,在 ~/.inputrc中添加
set completion-ignore-case on能使终端忽略大小写。
b. urxvt
还有个推荐说是urxvt,也就是rxvt的unicode版。在cygwin中,这是需要X 环境的。我没安装。
待实验。
c. mintty
这是我现在用的终端,是在cygwin的安装源中。无需设置,即可方便显示中文和输入中文。我让ls 显示颜色以及忽略大小写。
d. cmd
为什么不直接用cmd.exe 开 bash 呢? 也是无需设置显示中文和输入中文。但是,我不知道为什么我不用,或许是装13。
(2) Home路径设置
默认情况下,Home路径在/home/yourname,而/就是cygwin安装目录。很显然,你不会真把这个目录当作home目录,文件全存放在这吧?可以手动修改/etc/passwd文件来设置你喜欢的目录,路径格式使用cygwin风格,比如d:/tizzy目录,在此处应该为/cygdrive/d/tizzy 。
(3) 调用其他程序
居然cygwin是在windows上,说明windows上也有一些你比较顺手的程序,或者已经懒得去用cygwin中类似功能的程序。
为了能够在终端中调用,把每个程序的路径加入到PATH,我是直接加在系统PATH中。然后在目录下建个文件,起个你喜欢的名字,用来启动程序。比如:
我在widnows下用PDFXCview.exe来阅读pdf,安装路径在D:\Program Files\Tracker Software\PDF Viewer,把这个路径加入到系统PATH,在目录下建 pdfview 文件(是的,没有后缀),文件内容为
#!/bin/sh这样,就可以在终端中用pdfview 来打开pdf了。当然,你也可以不写pdfview文件,而用pdfxcview来启动,但是,这个名字很难记,是不是?!
run PDFXCview.exe "$@"
update:Jun 30,2011
本来以为上面设置就可以,后来打开pdf只能显示第一页,不知道原因。如果直接调用windows下的程序(因为已加入到PATH中),是可以正常打开,但是会占用一个终端,这是我不希望看到的。
实际上,cygwin提供了一个命令 cygstart,可以用来打开任何文件,默认会调用windows下的关联程序来打开,而且不占用终端。这正是我所需要的。
2011年6月24日星期五
MSYS 设置
Minimal GNU(POSIX)system on Windows,是一个小型的GNU环境,包括基本的bash ,make等等。Windows下最优秀的GNU环境(CygWin算什么啊?)。
I. 中文乱码解决方案
(1)ls显示中文不正常解决方法:
/etc/profile 中 添加
alias ls='ls --show-control-chars -F --color=tty'
(2)输入中文不正常解决方法:
在 /etc/inputrc.default 及 ~/.inputrc 中更改
set meta-flag on
set input-meta on
set output-meta on
set convert-meta off
II. 配置字体及颜色
可以通过C:\msys\1.0\msys.bat这个文件来修改,即安装路径下的msys.bat文件。
查找:
start rxvt -backspacekey -sl 2500 -fg %FGCOLOR% -bg %BGCOLOR% -sr -fn Courier-12 -tn msys -geometry 80×25 -e /bin/sh –login -i
I. 中文乱码解决方案
(1)ls显示中文不正常解决方法:
/etc/profile 中 添加
alias ls='ls --show-control-chars -F --color=tty'
(2)输入中文不正常解决方法:
在 /etc/inputrc.default 及 ~/.inputrc 中更改
set meta-flag on
set input-meta on
set output-meta on
set convert-meta off
II. 配置字体及颜色
可以通过C:\msys\1.0\msys.bat这个文件来修改,即安装路径下的msys.bat文件。
查找:
start rxvt -backspacekey -sl 2500 -fg %FGCOLOR% -bg %BGCOLOR% -sr -fn Courier-12 -tn msys -geometry 80×25 -e /bin/sh –login -i
可以修改为:
start rxvt -backspacekey -sl 2500 -fg white -bg black -sr -fn Courier-bold-14 -tn msys -geometry 100×40 -e /bin/sh –login -i这些属性值都可以随便自己设定,不过这一行一定要作为一行来保存!
字体如果使用truetype,界面会变得更丑,比如Courier New 。所以我还是老实使用默认的Courier。
III. 使用其他程序
在MSYS中提供了一些便利的unix-like工具,但你可能在windows下也有一些常用的工具,比如word,或者播放器之类的。这时可能通过编写脚本,使得在rxvt中能够直接调用这些工具。
看下面两个例子
在/bin 目录下添加/bin/splayer 文件,文件内容为:
#! /bin/sh
/d/Program\ Files/Tracker\ Software/PDF\ Viewer/pdfxcview.exe "$@"
这样,在rxvt中就可以通过 splayer 和 pdfview 调用 播放器和pdf阅读器了。
字体如果使用truetype,界面会变得更丑,比如Courier New 。所以我还是老实使用默认的Courier。
III. 使用其他程序
在MSYS中提供了一些便利的unix-like工具,但你可能在windows下也有一些常用的工具,比如word,或者播放器之类的。这时可能通过编写脚本,使得在rxvt中能够直接调用这些工具。
看下面两个例子
在/bin 目录下添加/bin/splayer 文件,文件内容为:
#! /bin/sh
/d/Program\ Files/SPlayer/splayer.exe "$@"
在/bin目录下添加/bin/pdfview 文件,文件内容为:
#! /bin/sh
/d/Program\ Files/Tracker\ Software/PDF\ Viewer/pdfxcview.exe "$@"
这样,在rxvt中就可以通过 splayer 和 pdfview 调用 播放器和pdf阅读器了。
2011年5月17日星期二
WS_POPUP WS_OVERLAPPED WS_CHILD
WS_POPUP WS_OVERLAPPED WS_CHILD
Overlapped Windows
An overlapped window is a top-level window that has a title bar, border, and client area; it is meant to serve as an application's main window. It can also have a window menu, minimize and maximize buttons, and scroll bars. An overlapped window used as a main window typically includes all of these components.
By specifying the WS_OVERLAPPED or WS_OVERLAPPEDWINDOW style in the CreateWindowEx function, an application creates an overlapped window. If you use the WS_OVERLAPPED style, the window has a title bar and border. If you use the WS_OVERLAPPEDWINDOW style, the window has a title bar, sizing border, window menu, and minimize and maximize buttons.
Pop-up Windows
Pop-up windows are top-level windows and are connected to the desktop window's child windows list. Applications usually use pop-up windows for dialog boxes. The main difference between pop-up and overlapped windows is that pop-up windows need not have captions and overlapped windows must have captions. When a pop-up window does not have a caption, it can be created without a border. Pop-up windows may own other top-level windows or be owned by other top-level windows or both. All pop-up windows have the WS_CLIPSIBLINGS style, even if it was not specified. Pop-up windows must not be created with the CW_USEDEFAULT value for either the position or the size of the window. Pop-up windows that use CW_USEDEFAULT will exist but will have no size or no position or both. Overlapped windows are usually reserved for your application's main window and, in fact, are sometimes called Main windows or Frame windows. Pop-up windows are usually used to communicate with the user in the form of Dialog boxes and Message boxes.
A pop-up window is a special type of overlapped window used for dialog boxes, message boxes, and other temporary windows that appear outside an application's main window. Title bars are optional for pop-up windows; otherwise, pop-up windows are the same as overlapped windows of the WS_OVERLAPPED style.
You create a pop-up window by specifying the WS_POPUP style in CreateWindowEx. To include a title bar, specify the WS_CAPTION style. Use the WS_POPUPWINDOW style to create a pop-up window that has a border and a window menu. The WS_CAPTION style must be combined with the WS_POPUPWINDOW style to make the window menu visible.
Child Windows
Child windows must have a parent window and are confined to the client area of their parent. This is the major distinction between child windows and overlapped and pop-up windows. Child window parents can be top-level windows or other child windows. Child windows are positioned from their parent window's upper-left corner and not from the upper-left of the screen as are top-level windows. Child windows are clipped to the client area of their parent. Controls in a dialog box are child windows whose parent is the dialog box. Child windows must not be created with the CW_USEDEFAULT value for either the position or size of the window. Child windows that use CW_USEDEFAULT will exist but will have no size or position or both.
A child window has the WS_CHILD style and is confined to the client area of its parent window. An application typically uses child windows to divide the client area of a parent window into functional areas. You create a child window by specifying the WS_CHILD style in the CreateWindowEx function.
A child window must have a parent window. The parent window can be an overlapped window, a pop-up window, or even another child window. You specify the parent window when you call CreateWindowEx. If you specify the WS_CHILD style in CreateWindowEx but do not specify a parent window, the system does not create the window.
A child window has a client area but no other features, unless they are explicitly requested. An application can request a title bar, a window menu, minimize and maximize buttons, a border, and scroll bars for a child window, but a child window cannot have a menu. If the application specifies a menu handle, either when it registers the child's window class or creates the child window, the menu handle is ignored. If no border style is specified, the system creates a borderless window. An application can use borderless child windows to divide a parent window's client area while keeping the divisions invisible to the user.
2011年5月4日星期三
字符集和字符编码(Charset & Encoding)
来源: 吴秦 原文链接
——每个软件开发人员应该无条件掌握的知识!
——Unicode伟大的创想!
相信大家一定碰到过,打开某个网页,却显示一堆像乱码,如"бЇЯАзЪСЯ"、"�????????"?还记得HTTP中的Accept-Charset、Accept-Encoding、Accept-Language、Content-Encoding、Content-Language等消息头字段?这些就是接下来我们要探讨的。
目录:
字符集(Charset):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息。而以计算机为基础的信息处理系统则是利用元件(硬件)不同状态的组合来存储和处理信息的。元件不同状态的组合能代表数字系统的数字,因此字符编码就是将符号转换为计算机可以接受的数字系统的数,称为数字代码。
ASCII字符集:主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
ASCII编码:将ASCII字符集转换为计算机可以接受的数字系统的数的规则。使用7位(bits)表示一个字符,共128字符;但是7位编码的字符集只能支持128个字符,为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。ASCII字符集映射到数字编码规则如下图所示:
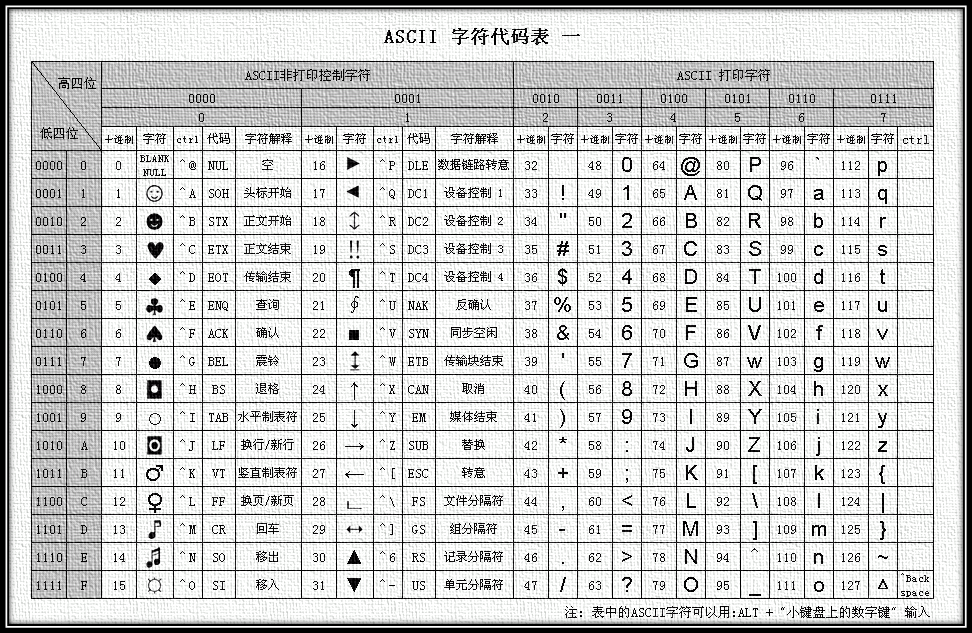
图1 ASCII编码表
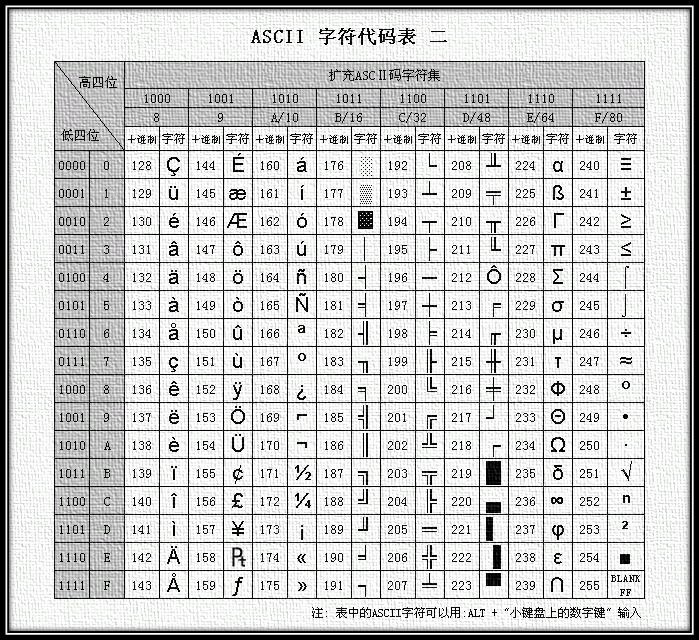
图2 扩展ASCII编码表
ASCII的最大缺点是只能显示26个基本拉丁字母、阿拉伯数目字和英式标点符号,因此只能用于显示现代美国英语(而且在处理英语当中的外来词如naïve、café、élite等等时,所有重音符号都不得不去掉,即使这样做会违反拼写规则)。而EASCII虽然解决了部份西欧语言的显示问题,但对更多其他语言依然无能为力。因此现在的苹果电脑已经抛弃ASCII而转用Unicode。
天朝专家把那些127号之后的奇异符号们(即EASCII)取消掉,规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,还把数学符号、罗马希腊的 字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
上述编码规则就是GB2312。GB2312或GB2312-80是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称GB0,由中国国家标准总局发布,1981年5月1日实施。GB2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。对于人名、古汉语等方面出现的罕用字,GB2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。下图是GB2312编码的开始部分(由于其非常庞大,只列举开始部分,具体可查看GB2312简体中文编码表):
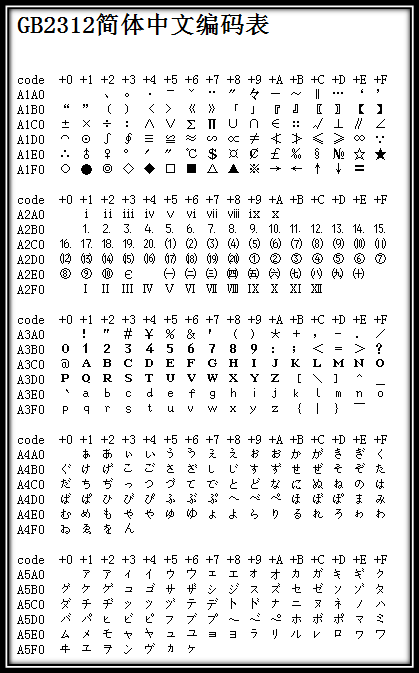
图3 GB2312编码表的开始部分
由于GB 2312-80只收录6763个汉字,有不少汉字,如部分在GB 2312-80推出以后才简化的汉字(如"啰"),部分人名用字(如中国前总理朱镕基的"镕"字),台湾及香港使用的繁体字,日语及朝鲜语汉字等,并未有收录在内。于是厂商微软利用GB 2312-80未使用的编码空间,收录GB 13000.1-93全部字符制定了GBK编码。根据微软资料,GBK是对GB2312-80的扩展,也就是CP936字码表 (Code Page 936)的扩展(之前CP936和GB 2312-80一模一样),最早实现于Windows 95简体中文版。虽然GBK收录GB 13000.1-93的全部字符,但编码方式并不相同。GBK自身并非国家标准,只是曾由国家技术监督局标准化司、电子工业部科技与质量监督司公布为"技术规范指导性文件"。原始GB13000一直未被业界采用,后续国家标准GB18030技术上兼容GBK而非GB13000。
GB 18030,全称:国家标准GB 18030-2005《信息技术 中文编码字符集》,是中华人民共和国现时最新的内码字集,是GB 18030-2000《信息技术 信息交换用汉字编码字符集 基本集的扩充》的修订版。与GB 2312-1980完全兼容,与GBK基本兼容,支持GB 13000及Unicode的全部统一汉字,共收录汉字70244个。GB 18030主要有以下特点:

——每个软件开发人员应该无条件掌握的知识!
——Unicode伟大的创想!
相信大家一定碰到过,打开某个网页,却显示一堆像乱码,如"бЇЯАзЪСЯ"、"�????????"?还记得HTTP中的Accept-Charset、Accept-Encoding、Accept-Language、Content-Encoding、Content-Language等消息头字段?这些就是接下来我们要探讨的。
目录:
- 1.基础知识
- 4.Accept-Charset/Accept-Encoding/Accept-Language/Content-Type/Content-Encoding/Content-Language
- 参考文献&进一步阅读
1.基础知识
计算机中储存的信息都是用二进制数表示的;而我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果。通俗的说,按照何种规则将字符存储在计算机中,如'a'用什么表示,称为"编码";反之,将存储在计算机中的二进制数解析显示出来,称为"解码",如同密码学中的加密和解密。在解码过程中,如果使用了错误的解码规则,则导致'a'解析成'b'或者乱码。字符集(Charset):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息。而以计算机为基础的信息处理系统则是利用元件(硬件)不同状态的组合来存储和处理信息的。元件不同状态的组合能代表数字系统的数字,因此字符编码就是将符号转换为计算机可以接受的数字系统的数,称为数字代码。
2.常用字符集和字符编码
常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等。计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。2.1. ASCII字符集&编码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本EASCII则可以勉强显示其他西欧语言。它是现今最通用的单字节编码系统(但是有被Unicode追上的迹象),并等同于国际标准ISO/IEC 646。ASCII字符集:主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
ASCII编码:将ASCII字符集转换为计算机可以接受的数字系统的数的规则。使用7位(bits)表示一个字符,共128字符;但是7位编码的字符集只能支持128个字符,为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。ASCII字符集映射到数字编码规则如下图所示:
图1 ASCII编码表
图2 扩展ASCII编码表
ASCII的最大缺点是只能显示26个基本拉丁字母、阿拉伯数目字和英式标点符号,因此只能用于显示现代美国英语(而且在处理英语当中的外来词如naïve、café、élite等等时,所有重音符号都不得不去掉,即使这样做会违反拼写规则)。而EASCII虽然解决了部份西欧语言的显示问题,但对更多其他语言依然无能为力。因此现在的苹果电脑已经抛弃ASCII而转用Unicode。
2.2. GBXXXX字符集&编码
计算机发明之处及后面很长一段时间,只用应用于美国及西方一些发达国家,ASCII能够很好满足用户的需求。但是当天朝也有了计算机之后,为了显示中文,必须设计一套编码规则用于将汉字转换为计算机可以接受的数字系统的数。天朝专家把那些127号之后的奇异符号们(即EASCII)取消掉,规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,还把数学符号、罗马希腊的 字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
上述编码规则就是GB2312。GB2312或GB2312-80是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称GB0,由中国国家标准总局发布,1981年5月1日实施。GB2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。对于人名、古汉语等方面出现的罕用字,GB2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。下图是GB2312编码的开始部分(由于其非常庞大,只列举开始部分,具体可查看GB2312简体中文编码表):
图3 GB2312编码表的开始部分
由于GB 2312-80只收录6763个汉字,有不少汉字,如部分在GB 2312-80推出以后才简化的汉字(如"啰"),部分人名用字(如中国前总理朱镕基的"镕"字),台湾及香港使用的繁体字,日语及朝鲜语汉字等,并未有收录在内。于是厂商微软利用GB 2312-80未使用的编码空间,收录GB 13000.1-93全部字符制定了GBK编码。根据微软资料,GBK是对GB2312-80的扩展,也就是CP936字码表 (Code Page 936)的扩展(之前CP936和GB 2312-80一模一样),最早实现于Windows 95简体中文版。虽然GBK收录GB 13000.1-93的全部字符,但编码方式并不相同。GBK自身并非国家标准,只是曾由国家技术监督局标准化司、电子工业部科技与质量监督司公布为"技术规范指导性文件"。原始GB13000一直未被业界采用,后续国家标准GB18030技术上兼容GBK而非GB13000。
GB 18030,全称:国家标准GB 18030-2005《信息技术 中文编码字符集》,是中华人民共和国现时最新的内码字集,是GB 18030-2000《信息技术 信息交换用汉字编码字符集 基本集的扩充》的修订版。与GB 2312-1980完全兼容,与GBK基本兼容,支持GB 13000及Unicode的全部统一汉字,共收录汉字70244个。GB 18030主要有以下特点:
- 与UTF-8相同,采用多字节编码,每个字可以由1个、2个或4个字节组成。
- 编码空间庞大,最多可定义161万个字符。
- 支持中国国内少数民族的文字,不需要动用造字区。
- 汉字收录范围包含繁体汉字以及日韩汉字
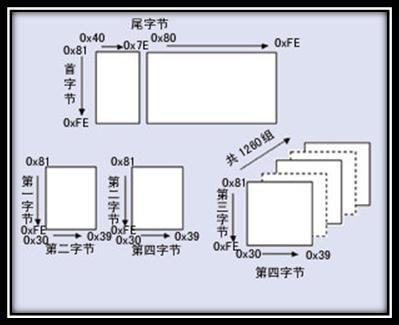
图4 GB18030编码总体结构
本规格的初版使中华人民共和国信息产业部电子工业标准化研究所起草,由国家质量技术监督局于2000年3月17日发布。现行版本为国家质量监督检验总局和中国国家标准化管理委员会于2005年11月8日发布,2006年5月1日实施。此规格为在中国境内所有软件产品支持的强制规格。2.3. BIG5字符集&编码
Big5,又称为大五码或五大码,是使用繁体中文(正体中文)社区中最常用的电脑汉字字符集标准,共收录13,060个汉字。中文码分为内码及交换码两类,Big5属中文内码,知名的中文交换码有CCCII、CNS11643。Big5虽普及于台湾、香港与澳门等繁体中文通行区,但长期以来并非当地的国家标准,而只是业界标准。倚天中文系统、Windows等主要系统的字符集都是以Big5为基准,但厂商又各自增加不同的造字与造字区,派生成多种不同版本。2003年,Big5被收录到CNS11643中文标准交换码的附录当中,取得了较正式的地位。这个最新版本被称为Big5-2003。
Big5码是一套双字节字符集,使用了双八码存储方法,以两个字节来安放一个字。第一个字节称为"高位字节",第二个字节称为"低位字节"。"高位字节"使用了0x81-0xFE,"低位字节"使用了0x40-0x7E,及0xA1-0xFE。在Big5的分区中:Unicode字符集&UTF编码0x8140-0xA0FE 保留给用户自定义字符(造字区) 0xA140-0xA3BF 标点符号、希腊字母及特殊符号,包括在0xA259-0xA261,安放了九个计量用汉字:兙兛兞兝兡兣嗧瓩糎。 0xA3C0-0xA3FE 保留。此区没有开放作造字区用。 0xA440-0xC67E 常用汉字,先按笔划再按部首排序。 0xC6A1-0xC8FE 保留给用户自定义字符(造字区) 0xC940-0xF9D5 次常用汉字,亦是先按笔划再按部首排序。 0xF9D6-0xFEFE 保留给用户自定义字符(造字区) 3.伟大的创想Unicode
——不得不单独说Unicode
像天朝一样,当计算机传到世界各个国家时,为了适合当地语言和字符,设计和实现类似GB232/GBK/GB18030/BIG5的编码方案。这样各搞一套,在本地使用没有问题,一旦出现在网络中,由于不兼容,互相访问就出现了乱码现象。
为了解决这个问题,一个伟大的创想产生了——Unicode。Unicode编码系统为表达任意语言的任意字符而设计。它使用4字节的数字来表达每个字母、符号,或者表意文字(ideograph)。每个数字代表唯一的至少在某种语言中使用的符号。(并不是所有的数字都用上了,但是总数已经超过了65535,所以2个字节的数字是不够用的。)被几种语言共用的字符通常使用相同的数字来编码,除非存在一个在理的语源学(etymological)理由使不这样做。不考虑这种情况的话,每个字符对应一个数字,每个数字对应一个字符。即不存在二义性。不再需要记录"模式"了。U+0041总是代表'A',即使这种语言没有'A'这个字符。
在计算机科学领域中,Unicode(统一码、万国码、单一码、标准万国码)是业界的一种标准,它可以使电脑得以体现世界上数十种文字的系统。Unicode 是基于通用字符集(Universal Character Set)的标准来发展,并且同时也以书本的形式[1]对外发表。Unicode 还不断在扩增, 每个新版本插入更多新的字符。直至目前为止的第六版,Unicode 就已经包含了超过十万个字符(在2005年,Unicode 的第十万个字符被采纳且认可成为标准之一)、一组可用以作为视觉参考的代码图表、一套编码方法与一组标准字符编码、一套包含了上标字、下标字等字符特性的枚举等。Unicode 组织(The Unicode Consortium)是由一个非营利性的机构所运作,并主导 Unicode 的后续发展,其目标在于:将既有的字符编码方案以Unicode 编码方案来加以取代,特别是既有的方案在多语环境下,皆仅有有限的空间以及不兼容的问题。
(可以这样理解:Unicode是字符集,UTF-32/ UTF-16/ UTF-8是三种字符编码方案。)3.1.UCS & UNICODE
通用字符集(Universal Character Set,UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。历史上存在两个独立的尝试创立单一字符集的组织,即国际标准化组织(ISO)和多语言软件制造商组成的统一码联盟。前者开发的 ISO/IEC 10646 项目,后者开发的统一码项目。因此最初制定了不同的标准。
1991年前后,两个项目的参与者都认识到,世界不需要两个不兼容的字符集。于是,它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作。从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会替超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。两个项目仍都存在,并独立地公布各自的标准。但统一码联盟和ISO/IEC JTC1/SC2都同意保持两者标准的码表兼容,并紧密地共同调整任何未来的扩展。在发布的时候,Unicode一般都会采用有关字码最常见的字型,但ISO 10646一般都尽可能采用Century字型。3.2.UTF-32
上述使用4字节的数字来表达每个字母、符号,或者表意文字(ideograph),每个数字代表唯一的至少在某种语言中使用的符号的编码方案,称为UTF-32。UTF-32又称UCS-4是一种将Unicode字符编码的协定,对每个字符都使用4字节。就空间而言,是非常没有效率的。
这种方法有其优点,最重要的一点就是可以在常数时间内定位字符串里的第N个字符,因为第N个字符从第4×Nth个字节开始。虽然每一个码位使用固定长定的字节看似方便,它并不如其它Unicode编码使用得广泛。3.3.UTF-16
尽管有Unicode字符非常多,但是实际上大多数人不会用到超过前65535个以外的字符。因此,就有了另外一种Unicode编码方式,叫做UTF-16(因为16位 = 2字节)。UTF-16将0–65535范围内的字符编码成2个字节,如果真的需要表达那些很少使用的"星芒层(astral plane)"内超过这65535范围的Unicode字符,则需要使用一些诡异的技巧来实现。UTF-16编码最明显的优点是它在空间效率上比UTF-32高两倍,因为每个字符只需要2个字节来存储(除去65535范围以外的),而不是UTF-32中的4个字节。并且,如果我们假设某个字符串不包含任何星芒层中的字符,那么我们依然可以在常数时间内找到其中的第N个字符,直到它不成立为止这总是一个不错的推断。其编码方法是: - 如果字符编码U小于0x10000,也就是十进制的0到65535之内,则直接使用两字节表示;
- 如果字符编码U大于0x10000,由于UNICODE编码范围最大为0x10FFFF,从0x10000到0x10FFFF之间 共有0xFFFFF个编码,也就是需要20个bit就可以标示这些编码。用U'表示从0-0xFFFFF之间的值,将其前 10 bit作为高位和16 bit的数值0xD800进行 逻辑or 操作,将后10 bit作为低位和0xDC00做 逻辑or 操作,这样组成的 4个byte就构成了U的编码。对于UTF-32和UTF-16编码方式还有一些其他不明显的缺点。不同的计算机系统会以不同的顺序保存字节。这意味着字符U+4E2D在UTF-16编码方式下可能被保存为4E 2D或者2D 4E,这取决于该系统使用的是大尾端(big-endian)还是小尾端(little-endian)。(对于UTF-32编码方式,则有更多种可能的字节排列。)只要文档没有离开你的计算机,它还是安全的——同一台电脑上的不同程序使用相同的字节顺序(byte order)。但是当我们需要在系统之间传输这个文档的时候,也许在万维网中,我们就需要一种方法来指示当前我们的字节是怎样存储的。不然的话,接收文档的计算机就无法知道这两个字节4E 2D表达的到底是U+4E2D还是U+2D4E。
为了解决这个问题,多字节的Unicode编码方式定义了一个"字节顺序标记(Byte Order Mark)",它是一个特殊的非打印字符,你可以把它包含在文档的开头来指示你所使用的字节顺序。对于UTF-16,字节顺序标记是U+FEFF。如果收到一个以字节FF FE开头的UTF-16编码的文档,你就能确定它的字节顺序是单向的(one way)的了;如果它以FE FF开头,则可以确定字节顺序反向了。3.4.UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码(定长码),也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。
UTF-8使用一至四个字节为每个字符编码:
- 128个US-ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。
- 带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要二个字节编码(Unicode范围由U+0080至U+07FF)。
- 其他基本多文种平面(BMP)中的字符(这包含了大部分常用字)使用三个字节编码。
- 其他极少使用的Unicode辅助平面的字符使用四字节编码。在处理经常会用到的ASCII字符方面非常有效。在处理扩展的拉丁字符集方面也不比UTF-16差。对于中文字符来说,比UTF-32要好。同时,(在这一条上你得相信我,因为我不打算给你展示它的数学原理。)由位操作的天性使然,使用UTF-8不再存在字节顺序的问题了。一份以utf-8编码的文档在不同的计算机之间是一样的比特流。
总体来说,在Unicode字符串中不可能由码点数量决定显示它所需要的长度,或者显示字符串之后在文本缓冲区中光标应该放置的位置;组合字符、变宽字体、不可打印字符和从右至左的文字都是其归因。所以尽管在UTF-8字符串中字符数量与码点数量的关系比UTF-32更为复杂,在实际中很少会遇到有不同的情形。
优点
- UTF-8是ASCII的一个超集。因为一个纯ASCII字符串也是一个合法的UTF-8字符串,所以现存的ASCII文本不需要转换。为传统的扩展ASCII字符集设计的软件通常可以不经修改或很少修改就能与UTF-8一起使用。
- 使用标准的面向字节的排序例程对UTF-8排序将产生与基于Unicode代码点排序相同的结果。(尽管这只有有限的有用性,因为在任何特定语言或文化下都不太可能有仍可接受的文字排列顺序。)
- UTF-8和UTF-16都是可扩展标记语言文档的标准编码。所有其它编码都必须通过显式或文本声明来指定。
- 任何面向字节的字符串搜索算法都可以用于UTF-8的数据(只要输入仅由完整的UTF-8字符组成)。但是,对于包含字符记数的正则表达式或其它结构必须小心。
- UTF-8字符串可以由一个简单的算法可靠地识别出来。就是,一个字符串在任何其它编码中表现为合法的UTF-8的可能性很低,并随字符串长度增长而减小。举例说,字符值C0,C1,F5至FF从来没有出现。为了更好的可靠性,可以使用正则表达式来统计非法过长和替代值(可以查看W3 FAQ: Multilingual Forms上的验证UTF-8字符串的正则表达式)。缺点
因为每个字符使用不同数量的字节编码,所以寻找串中第N个字符是一个O(N)复杂度的操作 — 即,串越长,则需要更多的时间来定位特定的字符。同时,还需要位变换来把字符编码成字节,把字节解码成字符。4.Accept-Charset/Accept-Encoding/Accept-Language/Content-Type/Content-Encoding/Content-Language
在HTTP中,与字符集和字符编码相关的消息头是Accept-Charset/Content-Type,另外主区区分Accept-Charset/Accept-Encoding/Accept-Language/Content-Type/Content-Encoding/Content-Language:
Accept-Charset:浏览器申明自己接收的字符集,这就是本文前面介绍的各种字符集和字符编码,如gb2312,utf-8(通常我们说Charset包括了相应的字符编码方案);
Accept-Encoding:浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate),(注意:这不是只字符编码);
Accept-Language:浏览器申明自己接收的语言。语言跟字符集的区别:中文是语言,中文有多种字符集,比如big5,gb2312,gbk等等;
Content-Type:WEB服务器告诉浏览器自己响应的对象的类型和字符集。例如:Content-Type: text/html; charset='gb2312'
Content-Encoding:WEB服务器表明自己使用了什么压缩方法(gzip,deflate)压缩响应中的对象。例如:Content-Encoding:gzip
Content-Language:WEB服务器告诉浏览器自己响应的对象的语言。参考文献&进一步阅读
- 百度百科. 字符集. http://baike.baidu.com/view/51987.htm, 2010-12-28
- 维基百科. 字符编码. http://zh.wikipedia.org/wiki/%E5%AD%97%E7%AC%A6%E7%BC%96%E7%A0%81, 2011-1-5
- 维基百科. ASCII. http://zh.wikipedia.org/wiki/ASCII, 2011-4-5
- 维基百科. GB2312. http://zh.wikipedia.org/wiki/GB_2312, 2011-3-17
- 维基百科. GB18030. http://zh.wikipedia.org/wiki/GB_18030, 2010-3-10
- 维基百科. GBK. http://zh.wikipedia.org/wiki/GBK, 2011-3-7
- 维基百科. Unicode. http://zh.wikipedia.org/wiki/Unicode, 2011-4-30
- Laruence. 字符编码详解(基础). http://www.laruence.com/2009/08/22/1059.html, 2009-8-22
- Jan Hunt. Character Sets and Encoding for Web Designers - UCS/UNICODE. http://www.uninetnews.com/other_standards/charset.php
2011年4月11日星期一
一次谷歌面试趣事
本文原始地址:一次谷歌面试趣事
很多年前我进入硅谷人才市场,当时是想找一份高级工程师的职位。如果你有一段时间没有面试过,根据经验,有个非常有用的提醒你应该接受,就是:你往往会在前几次面试中的什么地方犯一些错误。简单而言就是,不要首先去你梦想的公司里面试。面试中有多如牛毛的应该注意的问题,你可能全部忘记了,所以,先去几个不太重要的公司里面试,它们会在这些方面对你起教育(再教育)作用。
很多年前我进入硅谷人才市场,当时是想找一份高级工程师的职位。如果你有一段时间没有面试过,根据经验,有个非常有用的提醒你应该接受,就是:你往往会在前几次面试中的什么地方犯一些错误。简单而言就是,不要首先去你梦想的公司里面试。面试中有多如牛毛的应该注意的问题,你可能全部忘记了,所以,先去几个不太重要的公司里面试,它们会在这些方面对你起教育(再教育)作用。
我第一家面试的公司叫做gofish.com,据我所知,gofish这家公司如今的情况跟我当时面试时完全的不同。我几乎能打保票的说,当时我在那遇到的那些人都已不再那工作了,这家公司的实际情况跟我们这个故事并不是很相关。但在其中的面试却是十分相关的。对我进行技术性面试的人是一个叫做Guy的家伙。
Guy穿了一条皮裤子。众所周知,穿皮裤子的面试官通常是让人"格外"恐怖的。而Guy也没有任何让人失望的意思。他同样也是一个技术难题终结者。而且是一个穿皮裤子的技术难题终结者 —— 真的,我做不到他那样。
我永远不会忘记他问我的一个问题。事实上,这个问题是非常的普通 —— 在当时也是硅谷里标准的面试题。
问题是这样的:
假设这有一个各种字母组成的字符串,假设这还有另外一个字符串,而且这个字符串里的字母数相对少一些。从算法是讲,什么方法能最快的查出所有小字符串里的字母在大字符串里都有?
比如,如果是下面两个字符串:
String 1: ABCDEFGHLMNOPQRS
String 2: DCGSRQPOM
答案是true,所有在string2里的字母string1也都有。如果是下面两个字符串:
String 1: ABCDEFGHLMNOPQRS
String 2: DCGSRQPOZ
答案是false,因为第二个字符串里的Z字母不在第一个字符串里。
当他问题这个问题时,不夸张的说,我几乎要脱口而出。事实上,对这个问题我很有信心。(提示:我提供的答案对他来说显然是最糟糕的一种,从面试中他大量的各种细微表现中可以看出来)。
对于这种操作一种幼稚的做法是轮询第二个字符串里的每个字母,看它是否同在第一个字符串里。从算法上讲,这需要O(n*m)次操作,其中n是string1的长度,m是string2的长度。就拿上面的例子来说,最坏的情况下将会有16*8 = 128次操作。
一个稍微好一点的方案是先对这两个字符串的字母进行排序,然后同时对两个字串依次轮询。两个字串的排序需要(常规情况)O(m log m) + O(n log n)次操作,之后的线性扫描需要O(m+n)次操作。同样拿上面的字串做例子,将会需要16*4 + 8*3 = 88加上对两个字串线性扫描的16 + 8 = 24的操作。(随着字串长度的增长,你会发现这个算法的效果会越来越好)
最终,我告诉了他一个最佳的算法,只需要O(n+m)次操作。方法就是,对第一个字串进行轮询,把其中的每个字母都放入一个Hashtable里(成本是O(n)或16次操作)。然后轮询第二个字串,在Hashtable里查询每个字母,看能否找到。如果找不到,说明没有匹配成功。这将消耗掉8次操作 —— 这样两项操作加起来一共只有24次。不错吧,比前面两种方案都要好。
Guy没有被打动。他把他的皮裤子弄的沙沙响作为回应。"还有没有更好的?"他问道。
我的天?这个家伙究竟想要什么?我看看白板,然后转向他。"没有了,O(n+m)是你能得到的最好的结果了 —— 我是说,你至少要对每个字母至少访问一次才能完成这项操作 —— 而这个方案是刚好是对每个字母只访问一次"。我越想越确信我是对的。
他走到白板前,"如果这样呢 —— 假设我们有一个一定个数的字母组成字串 —— 我给每个字母分配一个素数,从2开始,往后类推。这样A将会是2,B将会是3,C将会是5,等等。现在我遍历第一个字串,把每个字母代表的素数相乘。你最终会得到一个很大的整数,对吧?然后 —— 轮询第二个字符串,用每个字母除它。如果除的结果有余数,这说明有不匹配的字母。如果整个过程中没有余数,你应该知道它是第一个字串恰好的子集了。这样不行吗?"
每当这个时候 —— 当某个人的奇思异想超出了你的思维模式时,你真的需要一段时间来跟上他的思路。现在他站在那里,他的皮裤子并没有帮助我理解他。
现在我想告诉你 —— Guy的方案(不消说,我并不认为Guy是第一个想出这招的人)在算法上并不能说就比我的好。而且在实际操作中,你很可能仍会使用我的方案,因为它更通用,无需跟麻烦的大型数字打交道。但从"巧妙水平"上讲,Guy提供的是一种更、更、更有趣的方案。
我没有得到这份职位。也许是因为我拒绝了他们提供给我的一些讨厌的工作内容和其它一些东西,但这都无所谓了。我还有更大更好的目标呢。
接着,我应聘了become.com。在跟CTO的电话面试中,他给我布置了一道"编程作业"。这个作业有点荒唐 —— 现在回想起来,大概用了我3天的时间去完成。我得到了面试,得到了那份工作 —— 但对于我来说,最大的收获是这道编程作业强迫我去钻研并有所获。我需要去开发一个网页爬虫,一个拼写检查/纠正器,还有一些其它的功能。不错的东西。然而,最终,我拒绝了这份工作。
终于,我来到了Google面试。我曾说过Google的面试过程跟外面宣传的很一致。冗长 —— 严格,但诚实的说,相当的公平。他们在各种面试过程中尽最大的努力去了解你、你的能力。并不是说他们在对你做科学研究,但我确信他们是努力这样做。
我在Google的第四场面试是一个女工程师,老实话,是一场很无聊的面试。在前面几场面试中我表现的很好,感觉到我的机会非常的大。我相信如果不做出什么荒唐事情来,十拿九稳我能得到这份工作。
她问了我一些关于排序或设计方面的非常简单的问题,我记不清了。但就在45分钟的面试快要结束时,她对我说"我还有一个问题。假设你有一个一定长度的由字母组成的字符串。你还有另外一个,短些。你如何才能知道所有的在较短的字符串里的字母在长字符串里也有?"
哇塞。Guy附身了。
现在,我完全可以马上结束这场面试。我可以对她说"哈哈,几个星期前我就知道答案啦!",这是事实。但就是在几个星期前被问到这个问题时 —— 我给出的也是正确的答案。这是我本来就知道答案的问题。看起来就好像是Guy为我的这次面试温习过功课一样。而且,可恶,人们通常是通过上网来搜集面试问题 —— 而我,我可以毫不客气的说,对于这些问题,我不需要任何"作弊"。我自己知道这些答案!
现在你们可能认为——就在她问出了问题之后,在我准备开始说出在脑海里构思完成的最后的演讲之前——你们可能会想,我应该是,当然该,从情理上讲,镇定的回答出这个问题,并且获得赞赏。可糟糕的是,事实并不是这样。打个比喻,就像是她问出来问题后,我在闹子里立即举起了手,并大叫着"我!嗨!嗨!我知道!让我来回答吧!"我的大脑试图夺走我对嘴巴的控制权(这事经常发生),幸亏我坚强的毅力让我镇定下来。
于是我开始回答。平静的。带着不可思议的沉着和优雅。带着一种故意表现出来的 —— 带着一种,我认为,只有那种完全的渊博到对古今中外、不分巨细的知识都精通的人才能表现出来的自信。
我轻描淡写的说出来那种很幼稚的方案,就好象是这种方案毫无价值。我提到了给它们排序,就好像是在给早期的《星际迷航》中的一个场景中的人物穿上红T恤似的。最后,平淡的,就好像是我决定了所有事情的好坏、算法上的效率,我说出了O(n+m)一次性方案。
我要告诉你——尽管我表明上的平静——这整个过程我却在做激烈的挣扎,内心里我在对自己尖着——"你个笨蛋,赶紧告诉她素数方案!"
当我完成了对一次性算法的解释后,她完全不出意外的认可的点了下头,并开始在笔记本上记录。这个问题她以前也许问过了一百次,我想大部分的人都能回答上来。她也许写的是"回答正确。无聊的面试。正确的回答了无聊的字符串问题。没有惊喜。无聊的家伙,但可以留下。"
我等了一会。我让这种焦灼的状态持续的尽可能的长。我可以发誓的说,如果再耽搁一分钟,我一定会憋出脑血栓、脱口说出关于素数的未解之谜。
我打破了沉默。"你知道吗,还有另外一个,可能是更聪明的算法。"
她二目空空的抬头看了一眼,仅在瞬间闪现过一丝希望。
"假设我们有一定长度的字符串。我们可以给每个字母分配一个素数,从2开始。然后我们把大字串中的每个字母代表的素数相乘得出一个数,用小字串中的每个字母代表的素数去除它。如果除的过程中没有产生余数,则小字串是大字串的一个子集。"
在此时,我猜,她看起来就像是Guy当时把相同的话说给我听时我表现出来的样子。而我演讲时泰然自若的表情没了,眼睛瞪大,说话时稍微带出来一些唾沫星子。
一会儿后,她不得不说了,"可是…等一下,有可能…是的,可以这样!可是如何…如果…噢,噢,可行!简洁!"
我得意洋洋的吸了一口气。我在我的面试记录里写下了"她给了我一个'简洁'的评语!"在她提出这个问题之前我就确信能得到这份工作,现在我更加确信了。还有一点我十分确信的是,我(更准确的说是Guy)给了她今天的好心情。
我在Google干了3年,生活的十分愉快。我在2008年辞职去到一个小公司里做CTO,之后又开办了一个自己的公司。大概是一年前,我偶然的在一个创业论坛会上遇到了Guy,他记不得我了,当我向他细述这段往事时,他对他那条皮裤子大笑不已。
话说回来,如果这个故事里有什么教育意义的话——永远不要冒失的首先去应聘你梦想的公司,应先去应聘那些你不看好的职位。你除了能从这些面试中获得经验外,你指不定能遇到某个能为你的更重要的面试铺路的人呢。事实上,这个经验在你生活中的很多其它事情上也适应。
说正经的,如果你有机会想找一个解决问题的高手——雇佣Guy比谁都强。那个家伙很厉害。
(在这些陈年旧账里发现的一点技术瑕疵:字母有可能重复而字符串可能会很长,所以必须要有统计。用那个最幼稚的解决方案时,当在大字符串里找到一个字符后就把它删掉,当这样仍然是 O(n*m)次。在Hashtable里我们会有一个key->value的计数。Guy的方案在这种情况下仍然好用。)
修改:11/30/10 —— 本文中提到的Guy看到了这篇文章,并在评论中做了澄清。值得一读。
订阅:
博文 (Atom)